Updated to improve clarity and styling where necessary.
Topological sorting is a fundamental concept in computer science, and when applied to parallel processing, it can unlock significant performance gains. By ordering tasks in a way that respects their dependencies, we can ensure that each task is executed only when its prerequisites have been met, minimizing idle time and maximizing throughput. In a parallel context, this means that multiple tasks can be executed simultaneously, as long as their dependencies have been satisfied. This approach has far-reaching implications for a wide range of applications, from compiler design to workflow management. In this blog post, we’ll delve into the specifics of parallelizing dependency sorting, exploring the algorithms and techniques that make it possible to efficiently schedule and execute complex task graphs.
Defining the Problem
Imagine we are implementing a task scheduler. A user can select N tasks to be scheduled with optional dependencies defined between them. The execution order of these tasks will be determined by the dependencies set between them. In other words, we want to sort the tasks according to their dependencies. How exactly do we solve such a problem?
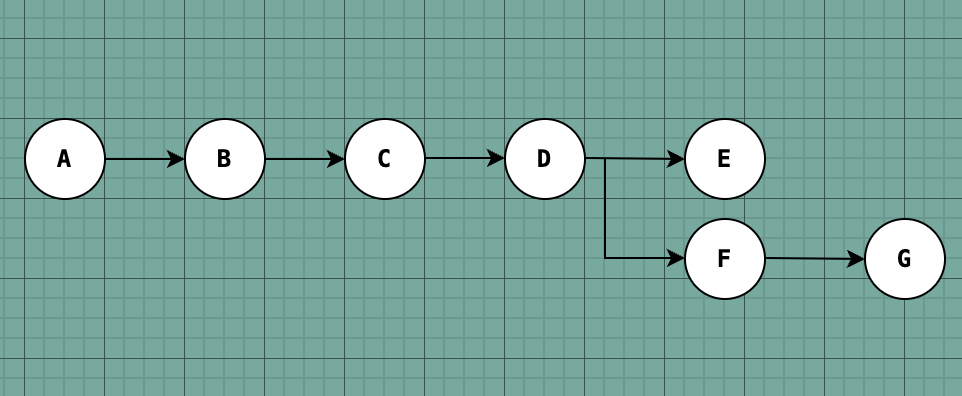
Let’s start by representing our list of tasks as a dependency tree, specifically as a Directed Acyclic Graph (DAG). Every task in the tree can be represented as a vertex in the graph. By nature of the data structure, a task can have successor(s) and/or dependent(s) as long as circular dependencies are not formed. The above diagram illustrates a simple example of a non-linear graph where a node could have multiple successors.
"Tree" and "graph" are used interchangeably due to the fact that all trees are inherently graphs since they don't allow cycles, but not all graphs are trees.
Outlining The Solution
Now that we are familiar with the problem let’s dive into the algorithm. Since we are dealing with dependencies, it would be natural for the scheduler to start executing tasks that do not have any dependencies. Once those tasks have finished executing, we can mark them as complete, remove them from the task queue, and start executing their successor tasks [as they no longer have any dependencies]. In terms of a graph, tasks to be executed are nodes that have no incoming edges or have an indegree of 0. Due to the level-by-level approach of this Topological Sorting algorithm, it would be considered BFS.
Instead of removing nodes without dependencies one-by-one like you normally would, you can scan the entire queue and remove all source nodes at once to execute tasks in parallel.
We can represent the graph as an adjacency map where the keys would be the tasks, and the values would be their dependents. First, we need to initialize a map that would keep track of our indegrees. For every task in the queue that has an indegree of 0: poll it, add it to our result list, and update the indegree map. Keep in mind that you will still need to check for empty graphs or graphs with circular dependencies (I’ll skip this step here).
Initializing The Indegrees
Let us define Task as an Object that has only a name and version. Given our graph as input, we need to first populate the initial indegrees. If we assume the input to contain null mappings, i.e. nodes with no dependents, then the solution is relatively simple:
public class TopologicalSort {
class Task {
private String name;
private Long version;
}
static List<Task> parallelSort(Map<Task, List<Task>> dependencyGraph) {
Map<Task, Integer> indegrees = new HashMap<>();
List<Task> sorted = new ArrayList<>();
// setup indegrees map
dependencyGraph.forEach(node -> {
indegrees.put(node.getKey(), node.getValue().size());
});
}
}Realistically, the graph would only contain elements that have dependencies. So we just need to find whatever node is not present in the graph but is still tied as a dependent. Using the Sets library will allow us to easily find that difference (there are other similar approaches). The logic can be slightly modified to below:
public class TopologicalSort {
class Task {
private int name;
private int version;
}
static List<Task> parallelSort(Map<Task, List<Task>> dependencyGraph) {
Map<Task, Integer> indegrees = new HashMap<>();
List<Task> sorted = new ArrayList<>();
// setup indegrees map
dependencyGraph.forEach(node -> {
Set<Task> diff = Sets.difference(new HashSet<>(dependencyGraph.keySet()), new HashSet<>(node.getValue()));
// dependency graph won't have null mappings (e.g. top most node)
if (diff.size() > 0) {
diff.forEach(dep -> indegrees.put(dep, 0));
indegrees.put(node.getKey(), node.getValue().size());
} else {
indegrees.put(node.getKey(), node.getValue().size());
}
});
}
}Sorting
Now, it’s time to move on to the heart of the algorithm. We can establish a linked-list queue of our tasks. As long as there are tasks still in the queue, we can keep picking off the ones that don’t have dependencies and updating the indegrees accordingly. The below would be a basic implementation of this approach:
public class TopologicalSort {
class Task {
private int name;
private int version;
}
static List<Task> parallelSort(Map<Task, List<Task>> dependencyGraph) {
Map<Task, Integer> indegrees = new HashMap<>();
List<Task> sorted = new ArrayList<>();
// setup indegrees map
dependencyGraph.forEach(node -> {
Set<Task> diff = Sets.difference(new HashSet<>(dependencyGraph.keySet()), new HashSet<>(node.getValue()));
// dependency graph won't have null mappings (e.g. top most node)
if (diff.size() > 0) {
diff.forEach(dep -> indegrees.put(dep, 0));
indegrees.put(node.getKey(), node.getValue().size());
} else {
indegrees.put(node.getKey(), node.getValue().size());
}
});
// loop and remove nodes without dependencies
// update the indegrees
Queue<Task> queue = new LinkedList<>(indegrees.keySet());
while (!queue.isEmpty()) {
List<Task> orphans = queue.stream().filter(t -> indegree.get(t) == 0);
if (CollectionUtils.isNotEmpty(orphans)) {
queue.removeAll(orphans);
dependencyGraph.entrySet().stream().forEach(entry -> {
indegrees.put(entry.getKey(), indegrees.get(entry.getKey()));
});
sorted.addAll(orphans);
}
}
return sorted;
}
}Not Quite There Yet…
There’s a tiny problem with this approach. With this hypothetical system, a user could define inherited dependencies. One such inherited dependency could be if D depends on C and B, but C also depends on B (using the diagram from earlier). It seems kind of redundant to define it in this way, but we’ll allow it here. To fix this, we can just factor out the common elements when computing the indegrees:
public class TopologicalSort {
class Task {
private int name;
private int version;
}
static List<Task> parallelSort(Map<Task, List<Task>> dependencyGraph) {
Map<Task, Integer> indegrees = new HashMap<>();
List<Task> sorted = new ArrayList<>();
// setup indegrees map
dependencyGraph.forEach(node -> {
Set<Task> diff = Sets.difference(new HashSet<>(dependencyGraph.keySet()), new HashSet<>(node.getValue()));
// dependency graph won't have null mappings (e.g. top most node)
if (diff.size() > 0) {
diff.forEach(dep -> indegrees.put(dep, 0));
indegrees.put(node.getKey(), node.getValue().size());
} else {
indegrees.put(node.getKey(), node.getValue().size());
}
});
// loop and remove nodes without dependencies
// update the indegrees
Queue<Task> queue = new LinkedList<>(indegrees.keySet());
while (!queue.isEmpty()) {
List<Task> orphans = queue.stream().filter(t -> indegree.get(t) == 0);
if (CollectionUtils.isNotEmpty(orphans)) {
queue.removeAll(orphans);
dependencyGraph.entrySet().stream().forEach(entry -> {
indegrees.put(entry.getKey(), indegrees.get(entry.getKey()));
Set<Task> common = new HashSet<>(orphans);
common.retainAll(new HashSet<>(entry.getValue()));
indegrees.put(entry.getKey(), indegrees.get(entry.getKey()) - common.size());
});
sorted.addAll(orphans);
}
}
return sorted;
}
}Remarks
And with that, we’ve wrapped up the algorithm. But you’re probably interested in finding out the time and space complexities. Using a graph of T nodes and D edges, coupled with our modified BFS approach, we would have a time complexity of O(T + D). This is because we loop through all T nodes, and subsequently all D edges to update the neighbors. As far as auxillary space is concerned, O(T) is required to store all nodes in the queue.